
This story begins with a simple question:
How do I remove XML comments in JavaScript?
The Internet hivemind converged on one general approach: regular expressions.
The most frequently recommended answer is:
str = str.replace(/<!--[\s\S]*?-->/g, ""); // bad, do not use
^^^^^^^^^^^^^^^^^^
There are known flaws with this family of regular expressions.
This discussion focuses on "Regexide", the act of identifying and replacing flawed regular expressions with other techniques that better reflect the intended effect.
Why XML Comments matter
XML is a popular format for storing and sharing data. It was explicitly designed for people and programs to read and write data.[1] From spreadsheets to save states, most modern software and games parse and write XML.
XML comments are special notes that parsers should not treat as data. XML comments start with <!-- and end with -->.
Technically XML comments must not contain the string -- within the comment body. Many programs and people write invalid XML comments, so parsers will typically allow for nested --.
The following XML comment is technically invalid but accepted by many parsers:
<!-- I used to be a programmer like you,
then I took an <!-- in the Kleene -->
(Kleene wrote a seminal paper[2] on regular expressions.)
How the regular expression works
The regular expression body /<!--[\s\S]*?-->/ has three parts:
A) <!-- matches the four literal characters
B) [\s\S]*? matches any number of characters
C) --> matches the three literal characters
In (B), [\s\S] matches any character. The *? is a "non-greedy quantifier" that instructs the regular expression engine to take the shortest match.
Example of greedy and non-greedy matches (click to show)
Consider the following string:
<!-- <!-- <!-- --> --> -->
The "greedy" /<!--[\s\S]*-->/ will match from the first <!-- to the last -->:
<!-- <!-- <!-- --> --> --> /<!--[\s\S]*-->/
The non-greedy /<!--[\s\S]*?-->/ will match from the first <!-- to the first -->:
<!-- <!-- <!-- --> --> --> /<!--[\s\S]*?-->/
The modern variant of the regular expression uses the /s flag:
str = str.replace(/<!--.*?-->/gs, ""); // even worse
^^^^^^^^^^^^^^
The /s flag modifies the . character class to include line terminators.
Usage in Open Source Projects
Many popular open source projects use problematic regular expressions.
Nunjucks used this regular expression within in the striptags filter expression:
let tags = /<\/?([a-z][a-z0-9]*)\b[^>]*>|<!--[\s\S]*?-->/gi;
PrettierJS used this regular expression in the build sequence:
const templateComments = template.match(/<!--.*?-->/gs);
RollupJS used this regular expression in the build sequence:
const bodyWithoutComments = data.body.replace(/<!--[\S\s]*?-->/g, '');
SheetJS used this regular expression in parsing:
str = str.replace(/<!--([\s\S]*?)-->/mg,"");
ViteJS used the nascent s flag to ensure . matches newline characters:
export const commentRE = /<!--.*?-->/gs
// Avoid matching the content of the comment
raw = raw.replace(commentRE, '<!---->')
VueJS 2 used regular expressions in processing:
text = text
.replace(/<!--([\s\S]*?)-->/g, '$1')
.replace(/<!\[CDATA\[([\s\S]*?)]]>/g, '$1');
WordPress used regular expressions in the word count calculator:
HTMLcommentRegExp: /<!--[\s\S]*?-->/g,
Element Plus used a similar regular expression to match blocks starting with <del> and ending with </del>:
const str = removeTag(value)
.replaceAll(/<del>.*<\/del>/g, '')
// ---------^^^^^^^^^^^^^^^^^^ -- start <del> end </del>
A rare consensus
Most resources recommend this approach.
Books recommend this approach. "Regular Expressions Cookbook"[3] section 9.9 explicitly recommends /<!--[\s\S]*?-->/ for matching XML comments.
StackOverflow Answers recommend this regular expression and variants such as /<!--[\s\S\n]*?-->/ (which are, for all practical purposes, equivalent).
ChatGPT4 has recommended the previous regular expression. It also generated code for a complete unrelated tag.
Bing AI proposed unrelated command line tools for JavaScript.
ChatGPT4 and Bing AI Screenshots (click to show)
ChatGPT4 Incorrect interpretation
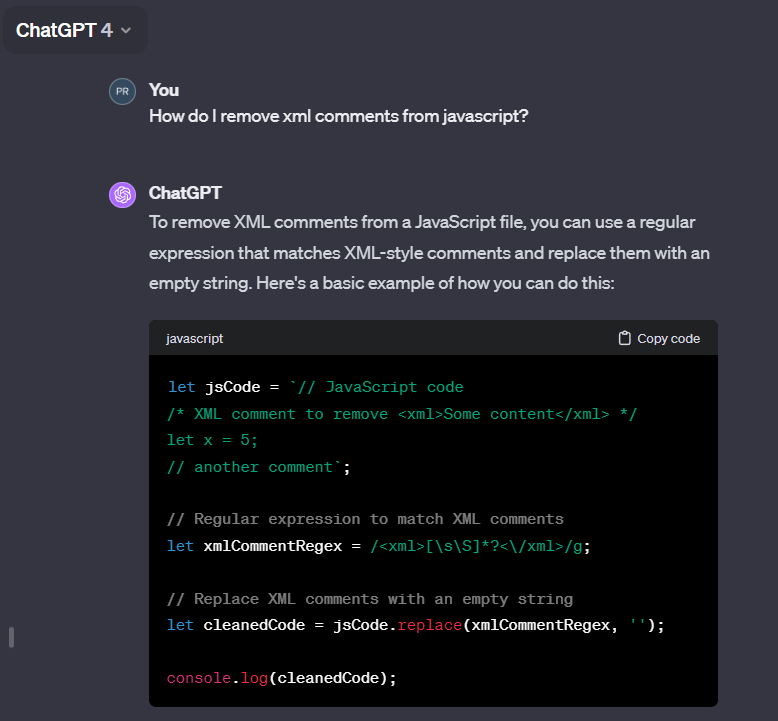
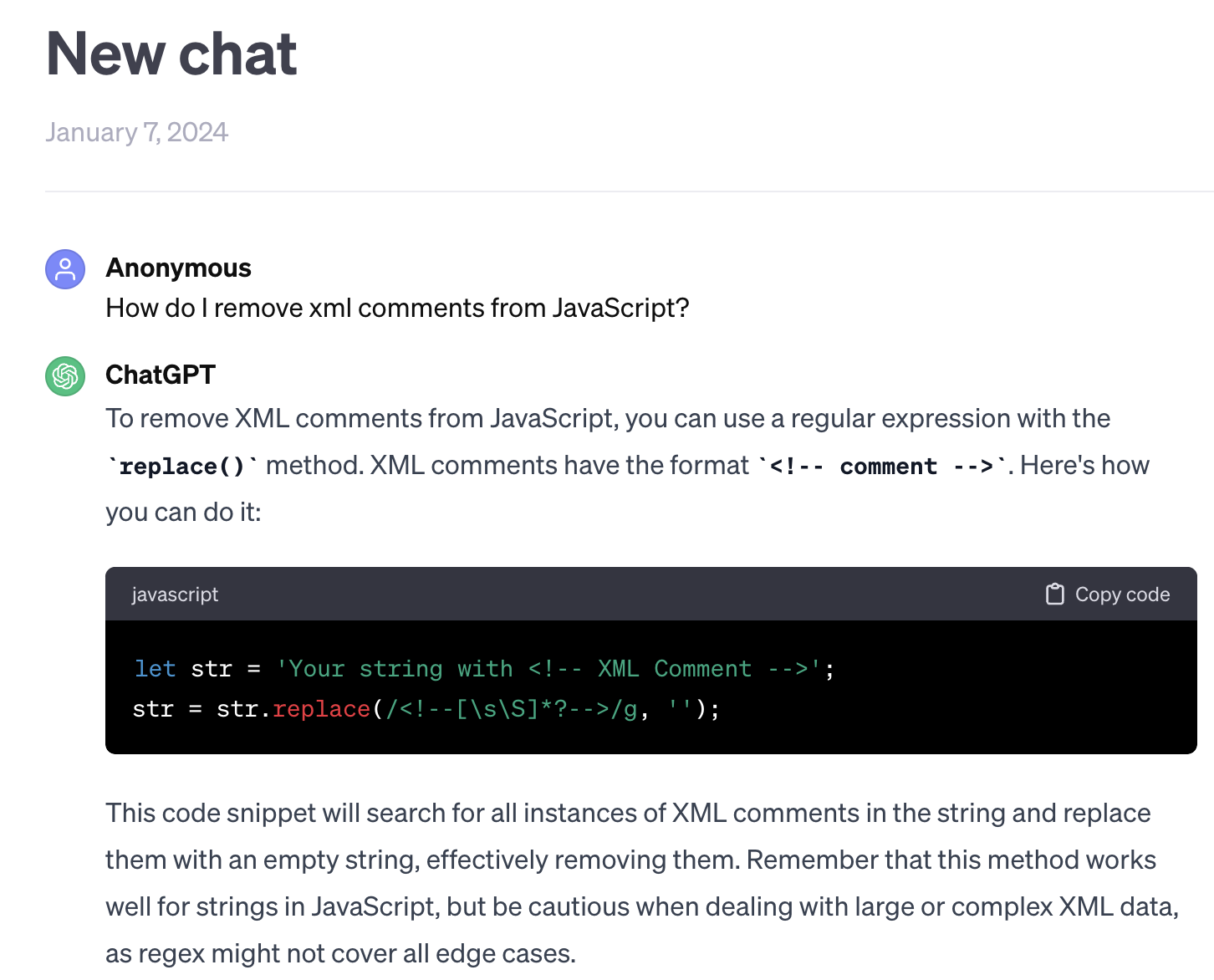
ChatGPT4 Correct interpretation, solution uses vulnerable regular expression
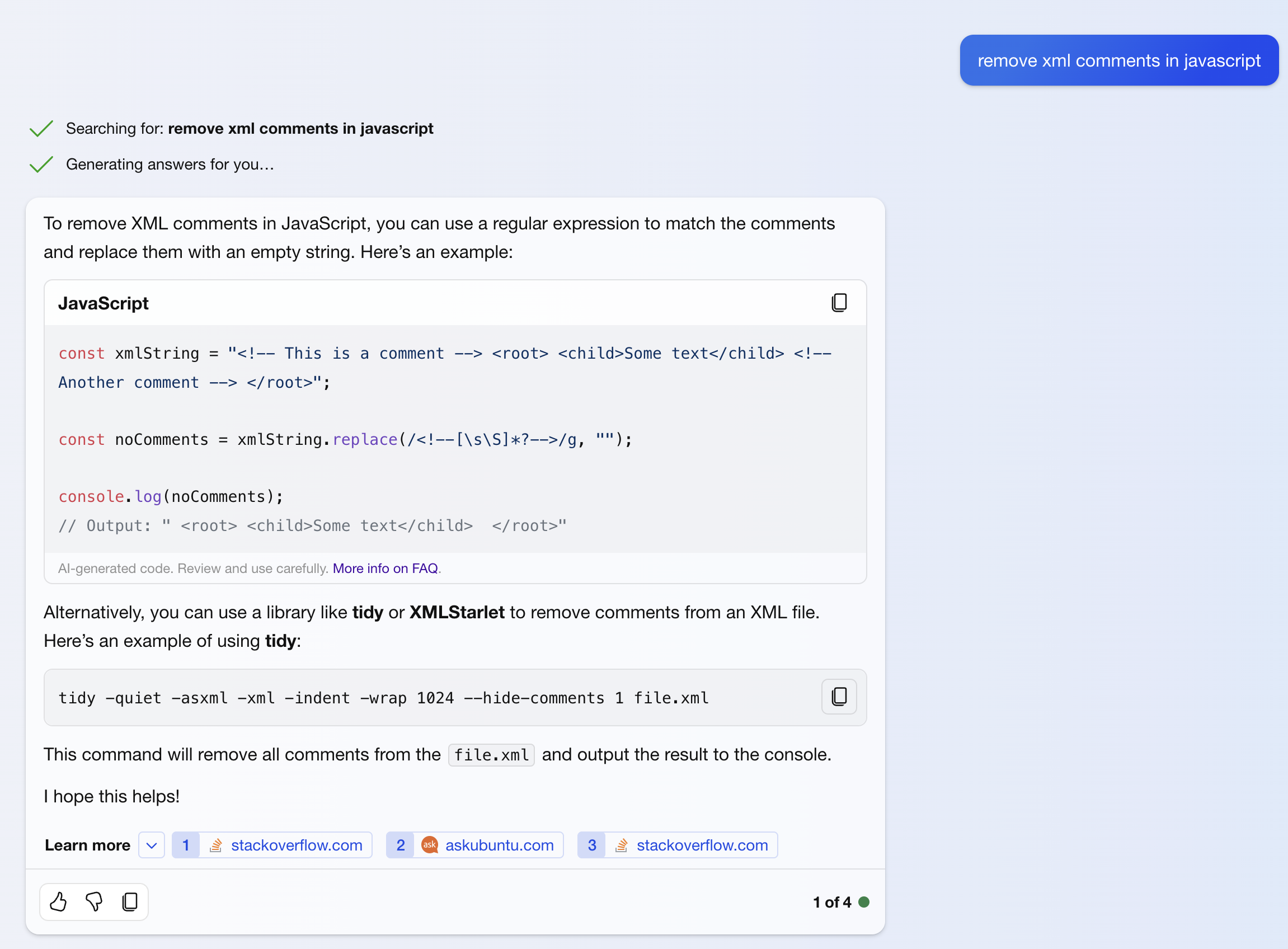
Bing AI Correct Interpretation, solution uses vulnerable regular expression
The Internet Failed Us
There are deep performance issues with the regular expression. To see this, consider a string that repeats the header part <!-- many times. In general, this type of string can be generated in JavaScript using String#repeat:
var string_repeated_65536_times = "<!--".repeat(65536);
The replace operation is surprisingly slow. Try the following snippet in a new browser window or NodeJS terminal:
// this loop doubles each time
for(var n = 64; n < 1000000; n*=2) {
var s = "<!--".repeat(n); // generate repeated string
console.time(n);
s.replace(/<!--([\s\S]*?)-->/mg,""); // replace
console.timeEnd(n);
}
Results are from local tests on a 2019 Intel i9 MacBook Pro. The following chart displays runtime in seconds (vertical axis) as a function of repetitions (horizontal axis). The quadratic trend line closely fits the data.
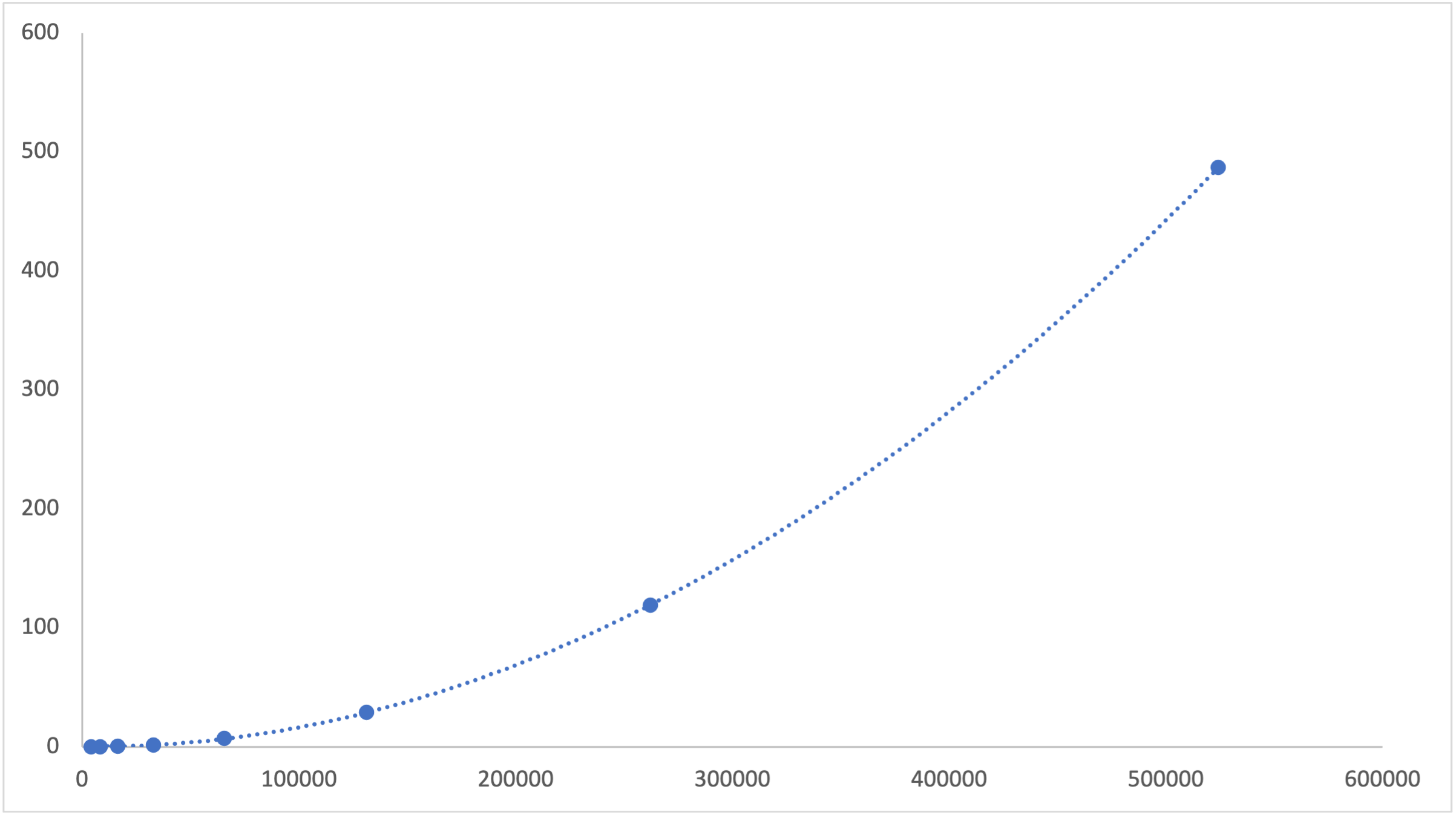
Download the raw data as a CSV
When the number of repetitions doubled, the runtime roughly quadrupled. This is a "quadratic" relationship.
Why the regular expression is slow
The regular expression matches a string that starts with <!-- and ends with -->. Consider a function that repeatedly looks for the <!-- string and tries to find the first --> that appears afterwards. Computer scientists classify this algorithm as "Backtracking"[4]:
function match_all_regex_comments(str) {
const results = [];
/* look for the first instance of <!-- */
let start_index = str.indexOf("<!--");
/* this loop runs while start_index is valid */
while(start_index > -1) {
/* look for the first instance of --> after <!-- */
let end_index = str.indexOf("-->", start_index + 4);
/* if --> is found, then we have a match! */
if(end_index > -1) {
/* add to array */
results.push(str.slice(start_index, end_index + 3));
/* start scanning from the end of the `-->` */
start_index = str.indexOf("<!--", end_index + 3);
}
else {
/* jump to the next potential starting point */
start_index = str.indexOf("<!--", start_index + 1);
}
}
/* return the final list */
return results;
}
Optimization
The keen-eyed reader will notice that the loop can be terminated once the search for --> fails (line 25 should be break;).
Engines designed for JavaScript regular expressions do not currently perform this optimization.
It can be shown that the runtime complexity of the modified algorithm is where is the string length and is the number of matches
If --> is not in the string, the scan str.indexOf("-->", start_index + 4) will look at every character in the string starting from start_index + 4. In the worst case, with repeated <!--, the scan will start from index 4, then index 8, then index 12, etc.
The following diagram shows the first three scans when running the function against the string formed by repeating <!-- 5 times. The <!-- matches are highlighted in yellow and the scans for the --> are highlighted in blue.
<!--<!--<!--<!--<!-- ^^^^ (first match of <!-- 0 - 3) ............ (scan for --> from index 4 to end) L - 4 characters <!--<!--<!--<!--<!-- ^^^^ (second match of <!-- 4 - 7) ........ (scan for --> from index 8 to end) L - 8 characters <!--<!--<!--<!--<!-- ^^^^ (third match of <!-- 8 - 11) .... (scan for --> from index 12 to end) L - 12 characters
For repetitions of <!--, the total string length is . There will be matches.
Mathematical Analysis (click to show)
The first scan will start on character 4 (end of the first match) and inspect characters (to the end of the string).
The second scan will start on character and inspect characters.
In general, the -th scan will start on character and inspect characters.
The total number of characters scanned when looking for the end tag (line 11 in the code) is:
In the worst case, the number of characters scanned is roughly proportional to the square of the length of the string. In "Big-O Notation", the complexity is . This is colloquially described as a "quadratic blowup".
Vulnerability
This is generally considered a vulnerability since relatively small data can cause browsers or servers to freeze for extended periods of time.
The official category for this weakness is "CWE-1333"[5] "Inefficient Regular Expression Complexity".
Some resources use the phrase "Catastrophic backtracking" to describe the issue.
A side note about Rust
Everyone writes high-performance code in Rust, right?
Rust does not have built-in support for regular expressions. Third-party libraries fill the gap.
The Rust regress[6] crate is designed for JavaScript regular expressions. It represents a true apples-to-apples comparison with JavaScript.
let re = regress::Regex::new(r"<!--([\s\S]*?)-->").unwrap();
let mut str = "<!--<!--<!--";
let _match = re.find(str);
Complete Example (click to show)
fn main() {
let re = regress::Regex::new(r"<!--([\s\S]*?)-->").unwrap();
/* construct string by repeating with itself */
let mut str = "<!--";
let mut _str = format!("{}{}", str, str);
let mut rept: u64 = 1;
for _i in 1..8 {
_str = format!("{}{}", str, str);
str = _str.as_str();
rept *= 2;
}
for _j in 1..11 {
/* test regular expression against string */
let start_time = std::time::Instant::now();
let _caps = re.find(str);
let elapsed_time = start_time.elapsed();
println!("{}: {:?}", rept, elapsed_time);
/* double string length by repeating with itself */
_str = format!("{}{}", str, str);
str = _str.as_str();
rept *= 2;
}
}
Results are from local tests on a 2019 Intel i9 MacBook Pro. regress shows the same quadratic behavior as other JavaScript regular expression engines.
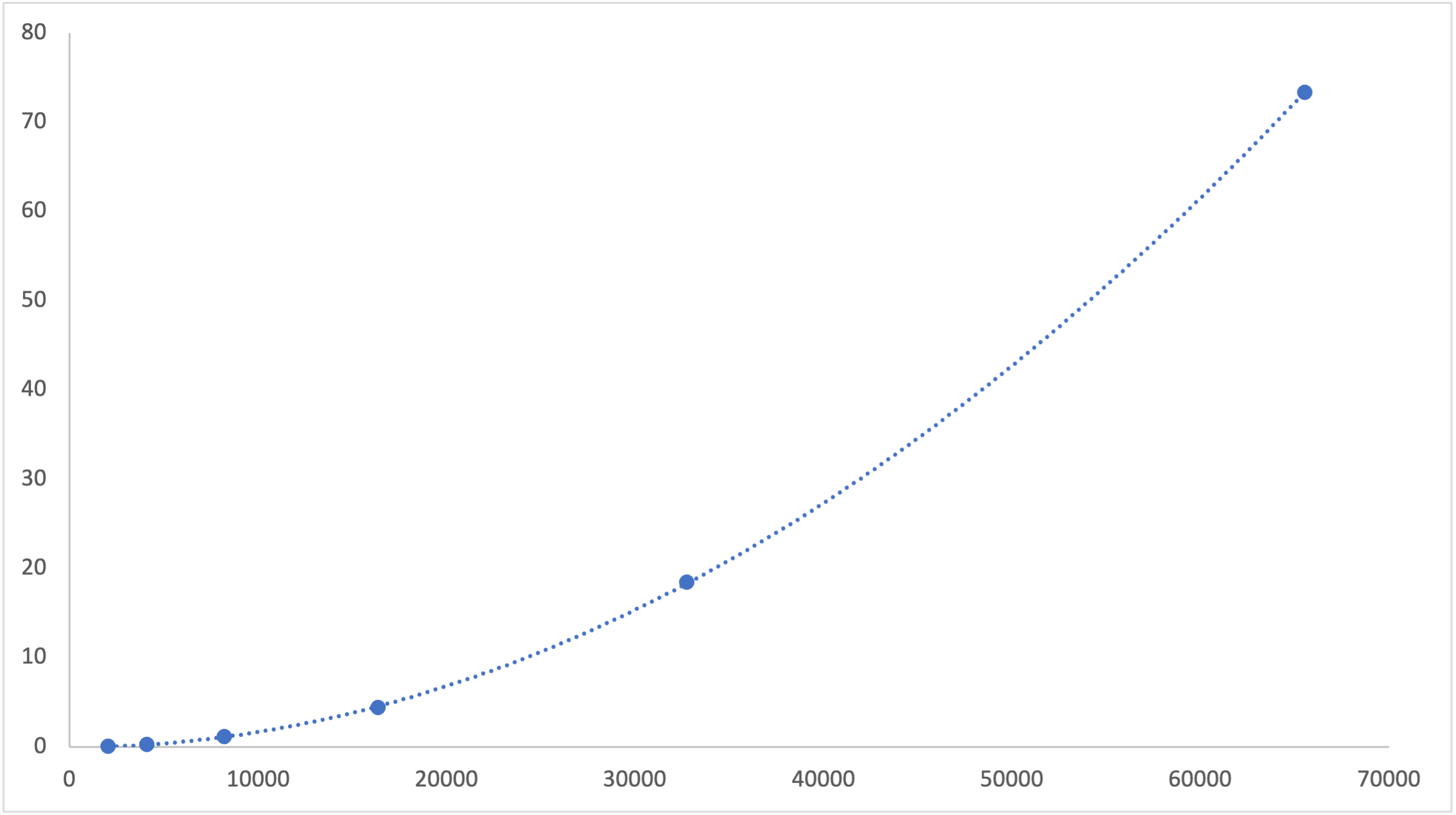
Download the raw data as a CSV
Workarounds
There are a few general approaches to address the issue.
Use a Different Engine
By limiting the supported featureset, other regular expression engines have stricter performance guarantees.
NodeJS
The re2[7] C++ engine sacrifices backreference and lookaround support for performance. There are bindings for many server-side programming languages.
The re2[8] NodeJS package is a native binding to the C++ engine and can be used in server-side environments. With modern versions of NodeJS, normal regular expressions can be wrapped with RE2:
var out = str.replace(new RE2(/<!--([\s\S]*?)-->/mg),""); // replace
Complete Example (click to show)
var RE2 = require("re2");
// this loop doubles each time
for(var n = 64; n < 100000000; n*=2) {
var s = "<!--".repeat(n); // generate repeated string
console.time(n);
s.replace(new RE2(/<!--([\s\S]*?)-->/mg),""); // replace
console.timeEnd(n);
}
The re2 implementation uses algorithms whose performance scales linearly with the size of the input.
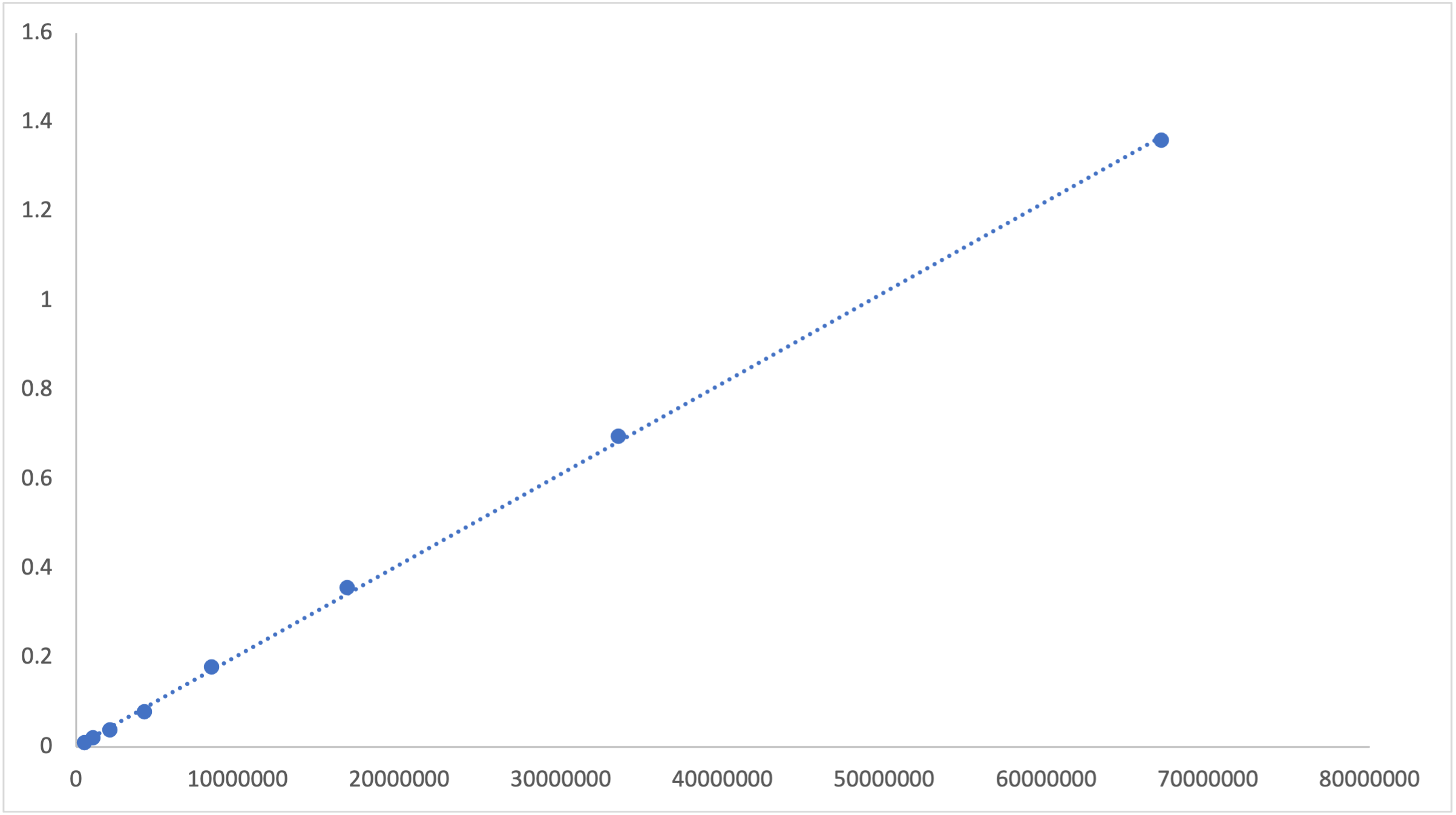
Download the raw data as a CSV
Rust
The Rust regex[9] crate sacrifices support for performance. It is the same tradeoff made by the re2 engine.
Since it does not use lookaround or backreferences, the original regular expression is compatible with the regex crate:
let re = regex::Regex::new(r"<!--([\s\S]*?)-->").unwrap();
let mut str = "<!--<!--<!--";
let _match = re.find(str);
Complete Example (click to show)
fn main() {
let re = regex::Regex::new(r"<!--([\s\S]*?)-->").unwrap();
/* construct string by repeating with itself */
let mut str = "<!--";
let mut _str = format!("{}{}", str, str);
let mut rept: u64 = 1;
for _i in 1..25 {
_str = format!("{}{}", str, str);
str = _str.as_str();
rept *= 2;
}
for _j in 1..11 {
/* find all matches */
let start_time = std::time::Instant::now();
let _caps = re.captures(str);
let elapsed_time = start_time.elapsed();
println!("{}: {:?}", rept, elapsed_time);
/* double string length by repeating with itself */
_str = format!("{}{}", str, str);
str = _str.as_str();
rept *= 2;
}
}
The Rust regex implementation uses algorithms whose performance scales linearly with the size of the input.
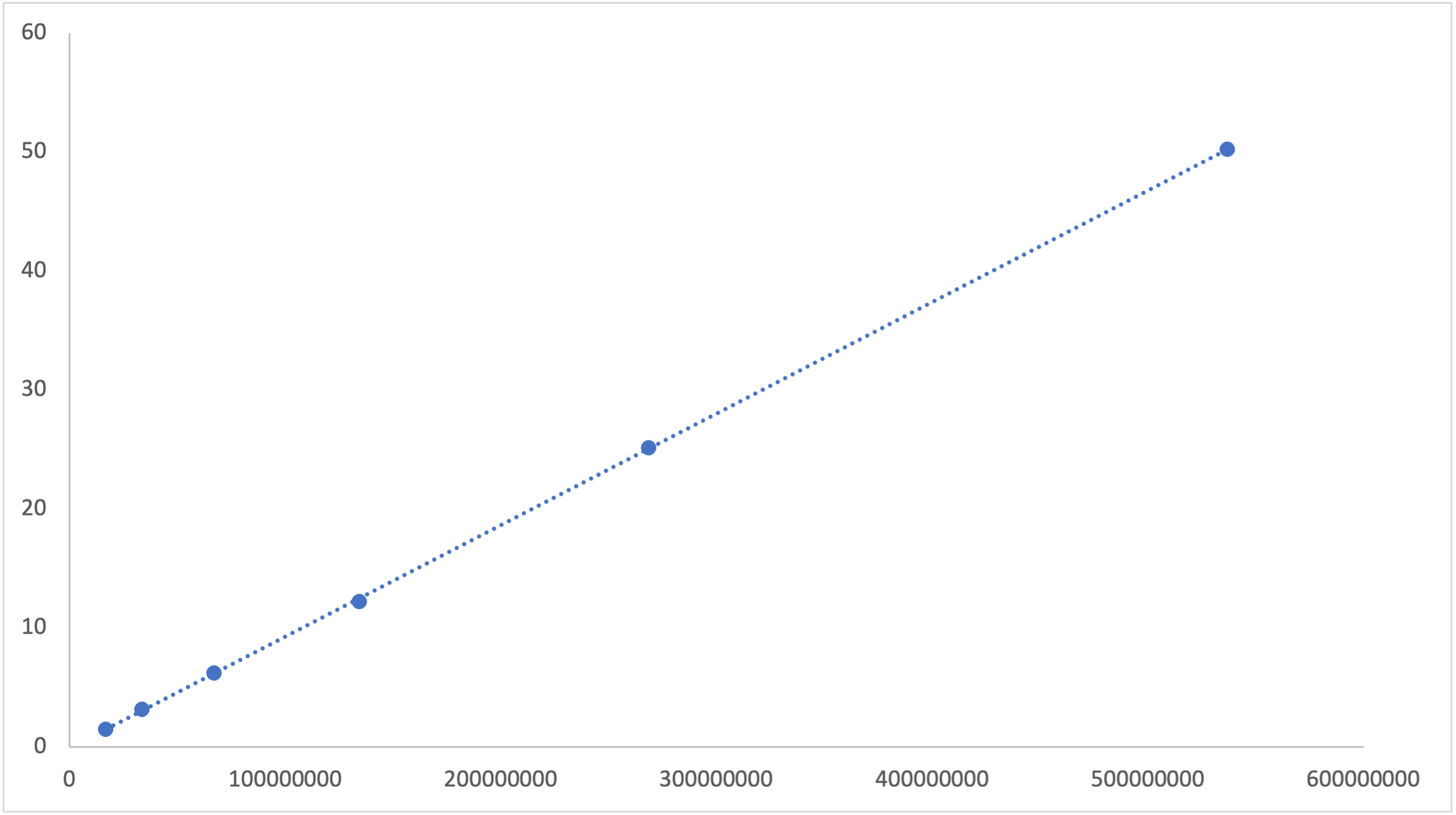
Download the raw data as a CSV
Exogenous Constraints
Most problems have additional constraints. Addressing the constraints allow for more precise regular expressions with better performance.
For the problem of matching comments, various specifications impose limitations.
XML Comments
The XML 1.0 specification[10] disallows -- within comments.
(this comment is not valid in XML 1.0)
<!-- - .... .. ... / -.-. --- -- -- . -. - / .. ... / .. -. ...- .- .-.. .. -.. -->
PrettierJS uses a regular expression in the MDX parser that enforces the XML constraint:
const COMMENT_REGEX = /<!---->|<!---?[^>-](?:-?[^-])*-->/;
Commonly-used regular expression engines can optimize for this pattern and avoid backtracking.
Spreadsheet Engines
The XML parser in Excel powering the Excel Workbook (XLSX) format expects proper XML comments with no -- in the comment body.
The XML parser in Excel powering the Excel 2003-2004 (SpreadsheetML) format allows -- in the comment body.
HTML Comments
The HTML5 standard[11] permits -- but forbids <!-- within comment text. For example, the following comment is not valid according to the standard:
<!-- I used to be a programmer like you, then I took an <!-- in the Kleene -->
yt-dlp uses a regular expression with a negative lookahead to ensure <!-- does not appear in the body:
html = re.sub(r'<!--(?:(?!<!--).)*-->', '', html)
This expression allows -- but disallows <!-- in the comment body. In practice, it will match comments starting from the innermost <!--. Using the previous example:
<!-- I used to be a programmer like you, then I took an <!-- in the Kleene -->
Web Browsers
Web browsers generally allow <!-- in comments. Text between the first <!-- and the first --> are treated as a comment. For example, consider the following HTML:
<pre><!-- this is a nested comment <!-- --> --> more text</pre>
| |^^^^^^^^^^^^^^ --- content
| this is interpreted as a comment |
This exact HTML code is added below:
--> more text
Chromium and other browsers will display --> more text
Remove the Regular Expression
Regular expression operations can be reimplemented using standard string operations.
For example, the replacement
str = str.replace(/<!--([\s\S]*?)-->/, "");
can be rewritten with a loop. The core idea is to collect non-commented fragments:
function remove_xml_comments(str) {
const START = "<!--", END = "-->";
const results = [];
/* this index tracks the last analyzed character */
let last_index = 0;
/* look for the first instance of <!-- */
let start_index = str.indexOf(START);
/* this loop runs while start_index is valid */
while(start_index > -1) {
/* add the fragment that precedes the comment */
results.push(str.slice(last_index, start_index));
last_index = start_index;
/* look for the first instance of --> after <!-- */
let end_index = str.indexOf(END, start_index + START.length);
/* if --> is found, then we have a match! */
if(end_index > -1) {
/* skip the comment */
last_index = end_index + END.length;
/* search for next comment open tag */
start_index = str.indexOf(START, last_index);
}
/* if there is no end comment tag, stop processing */
else break;
}
/* add remaining part of string */
results.push(str.slice(last_index));
/* concatenate the fragments */
return results.join("");
}
Validate Data
In the places where ViteJS used the vulnerable regular expression, the text was validated using a separate HTML parser.
It is still strongly recommended to replace the regular expression.
Limit to Trusted Data
PrettierJS and RollupJS use the vulnerable regular expression in internal scripts. The expressions are not used or added in websites. The data sources are trusted and malformed data can be corrected manually.
Special Thanks
Special thanks to Asadbek, Jardel, and members of the SheetJS team for early feedback.
See "Origin and Goals" in the Extensible Markup Language (XML) 1.0 specification. ↩︎
The theoretical underpinnings of modern regular expressions were established in the working paper "Representation of Events in Nerve Nets and Finite Automata" ↩︎
See "9.9 Remove XML-Style Comments" on the official site for the book. ↩︎
See the Wikipedia article for "Backtracking" for more details and resources. ↩︎
See the definition in the "CWE List" for more details and resources. ↩︎
See the listing for
regresscrate for more details. ↩︎See the
google/re2project on GitHub for more details. ↩︎See the listing for the
re2NodeJS package for more details. ↩︎See the listing for
regexcrate for more details. ↩︎See "Comments" in the XML 1.0 specification. ↩︎
See "Comments" in the WHATWG HTML Living Standard. ↩︎